


NOTA DE TAPA
UN ENFOQUE PASO A PASO PARA REDUCIR LA HUELLA DE CO₂ A TRAVÉS DE UNIDADES SRU
A partir de casos industriales, el trabajo analiza cómo la tecnología WSA (Wet gas Sulfuric Acid) en unidades SRU (Sulfur Recovery Unit) permite aprovechar mejor el calor del proceso, generar más vapor de alta presión y avanzar en la reducción de emisiones de CO₂ en refinerías.
Por Juan A. Ruquet (Topsoe A/S)
Este trabajo fue seleccionado del 7º Congreso Latinoamericano y del Caribe de Refinación del IAPG.
Introducción
La urgencia de descarbonizar los procesos industriales está en el centro de las agendas globales. Una solución viable radica en un enfoque paso a paso, donde cada etapa contribuye a reducciones acumulativas en las emisiones de CO₂. Este artículo explora una de esas etapas para la industria de refinación: el aumento de la producción de vapor de alta presión en las Unidades de Recuperación de Azufre (SRU, de sus siglas en inglés), evitando o reduciendo así el uso de combustibles fósiles.
El artículo analiza el proceso de maximizar la producción de vapor de alta presión aprovechando las reacciones exotérmicas involucradas en la oxidación del sulfuro de hidrógeno (H₂S) a ácido sulfúrico (H₂SO₄). Este proceso genera casi cuatro veces más calor de reacción en comparación con la producción de azufre elemental, lo que representa un método de producción de energía altamente eficiente. Se destaca la probada tecnología WSA, que hace posibles estos procesos. Esta tecnología puede instalarse como la única SRU, añadirse a SRUs existentes para aumentar la capacidad y conversión global, tratar gases que contienen amoníaco o servir como tratamiento de gases residuales de una SRU existente.
A través de una serie de estudios de caso industriales, el artículo ilustra las ventajas de este enfoque para reducir la huella total de CO₂ de la refinería. Estos estudios de caso sirven como evidencia convincente del potencial de las estrategias de descarbonización para impactar las emisiones de carbono.
Desarrollo
1. EL PANORAMA DE LA DESCARBONIZACIÓN
La industria global de refinación sigue siendo un contribuyente significativo a las emisiones totales de Gases de Efecto Invernadero (GHG, de sus siglas en inglés). Sin una acción rápida y decisiva, se proyecta que las emisiones permanezcan elevadas en el futuro previsible. Los objetivos nacionales de descarbonización exigen reducciones ambiciosas, con Estados Unidos apuntando a una disminución del 35% en las emisiones de producción de refinación para 2030 y una ambiciosa reducción del 90% para 2050¹. De manera alentadora, una reducción del 20% para mediados de la década de 2030 parece alcanzable mediante la implementación de medidas económicas actuales, sin necesidad de apoyo gubernamental adicional.
(1) Decarbonizing Chemicals and Refining - Pathways to Commercial Liftoff (energy.gov)
Las refinerías ofrecen oportunidades únicas para los esfuerzos de descarbonización. Una refinería típica con una capacidad de 10 millones de toneladas de crudo por año (MTA) puede generar aproximadamente 2 millones de toneladas (Mt) de CO₂ equivalente (CO₂eq) en emisiones de Alcance 1 y 2². Estas emisiones pueden mitigarse de manera efectiva mejorando la eficiencia energética general tanto de los procesos principales como de los auxiliares dentro de la infraestructura existente de la refinería. Las tecnologías actuales y los procedimientos establecidos ofrecen una vía hacia reducciones significativas de CO₂, con las SRU desempeñando potencialmente un papel importante.
1.1. Prácticas establecidas: el proceso Claus predomina
El panorama moderno de la refinación depende en gran medida del proceso Claus modificado para la recuperación de azufre. Esta tecnología ampliamente establecida utiliza una serie de etapas catalíticas para convertir el sulfuro de hidrógeno (H₂S) en azufre elemental. Sin embargo, aunque el proceso Claus ofrece una solución confiable, presenta limitaciones en cuanto a la maximización de la captura de energía y la reducción del impacto ambiental.
Los avances técnicos ofrecen un camino hacia un mejor desempeño ambiental. En 1980, Topsoe introdujo un proceso revolucionario de recuperación de azufre: la tecnología WSA. Inicialmente considerado como una solución rentable para el tratamiento de gases residuales con bajo contenido de azufre, el proceso WSA demostró rápidamente su aplicabilidad más amplia.
El proceso de conversión directa de H₂S a ácido sulfúrico, el producto final para gran parte del azufre recuperado, surgió como un desafío para la tecnología Claus modificada. Sin embargo, aunque la industria reconocía el potencial de mejorar la rentabilidad y reducir el impacto ambiental mediante la producción de ácido sulfúrico, las limitaciones logísticas, principalmente relacionadas con la demanda local, dificultaron su adopción generalizada. Es importante destacar que, en ese momento, ni los procesos WSA ni Claus se consideraban comúnmente como soluciones de descarbonización.
(2) Global oil refining's contribution to greenhouse gas emissions from 2000 to 2021: The Innovation (cell.com)
1.2. Dando un giro: ventajas termodinámicas de la tecnología WSA
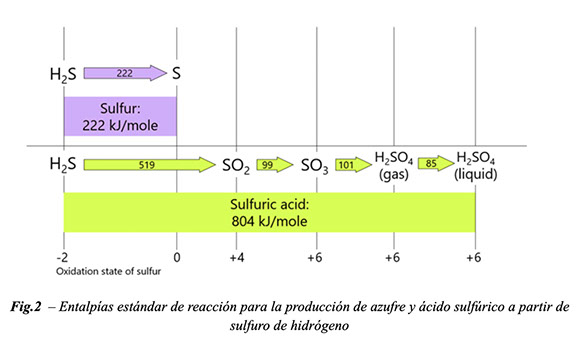
El potencial de descarbonización para una refinería determinada al pasar del proceso Claus al proceso WSA para la recuperación de azufre depende del contenido de azufre del crudo específico que se utiliza como materia prima. La diferencia en la termodinámica de estos dos procesos desempeña un papel crucial en la determinación de la producción total de energía.
Al convertir H₂S en azufre elemental, el azufre pasa del estado de oxidación -2 al estado de oxidación 0. Este es un proceso exotérmico, que genera aproximadamente 222 kJ por mol de H₂S procesado.
Al convertir H₂S en ácido sulfúrico, el azufre pasa en dos etapas del estado de oxidación -2 primero al estado de oxidación +4 y finalmente al estado de oxidación +6. Las reacciones involucradas también son exotérmicas, pero con un salto de entalpía casi cuatro veces mayor, generando en total aproximadamente 804 kJ por mol de H₂S procesado.
Las diferentes entalpías de reacción de los procesos Claus y WSA, como se muestra en la Figura 2, resultan en una producción de energía sustancialmente mayor en una planta WSA en comparación con una planta Claus. Al aprovechar esta energía exotérmica liberada durante el proceso en forma de vapor de alta presión, las refinerías pueden reducir significativamente su huella total de CO₂.
1.3. Impulsando la descarbonización: la ventaja del crudo ácido
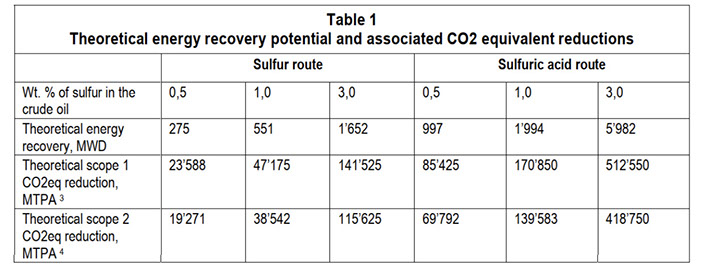
Las refinerías que procesan crudos ácidos, caracterizados por un mayor contenido de azufre, son las que pueden obtener los beneficios más significativos al pasar al proceso WSA. La Tabla 1 presenta un desglose del potencial teórico de recuperación de energía y de las reducciones asociadas de CO₂ equivalente entre los procesos Claus y WSA, asumiendo la conversión completa de H₂S a azufre elemental o a ácido sulfúrico, respectivamente.
Si bien el rendimiento energético teórico de la ruta del ácido es considerable, obviamente existen limitaciones prácticas. La captura total de energía a partir de la conversión de H₂S en azufre o ácido es inalcanzable. Además, la sustitución total de las plantas Claus existentes por unidades WSA parece logística y financieramente impracticable.
No obstante, recuperar incluso el 90% de la energía liberada durante la producción de ácido sulfúrico representa un argumento convincente para una transición gradual. Los procesos Claus modernos requieren el uso de reboilers en las Unidades de Tratamiento de Gases Residuales (TGTU, por sus siglas en inglés) basadas en aminas, los cuales consumen una cantidad significativa de vapor de baja presión. Este consumo de vapor de baja presión limita el potencial de descarbonización de la ruta del azufre, ya que el vapor de baja presión producido dentro del proceso Claus es insuficiente para satisfacer la demanda de la TGTU.
Reemplazar o modernizar plantas Claus antiguas con nuevas unidades WSA surge como una estrategia sólida para reducir las emisiones de carbono en comparación con la construcción de unidades Claus completamente nuevas. Un cambio progresivo de la producción de azufre a la producción de ácido brinda a las refinerías una valiosa experiencia en el manejo de ácido y facilita el establecimiento de acuerdos sólidos de venta a largo plazo. A medida que las refinerías incrementan gradualmente la asignación de gases ácidos desde la producción de azufre, menos eficiente energéticamente, hacia la producción de ácido, más eficiente, la huella de carbono total de la refinería disminuye.
(3) Factor de emisión, gas natural 0,068 kg CO2eq/MJ
(4) Intensidad de carbono 200 gCO2eq/kWh
2. ESTUDIOS DE CASO
2.1. Estudio de Caso 1
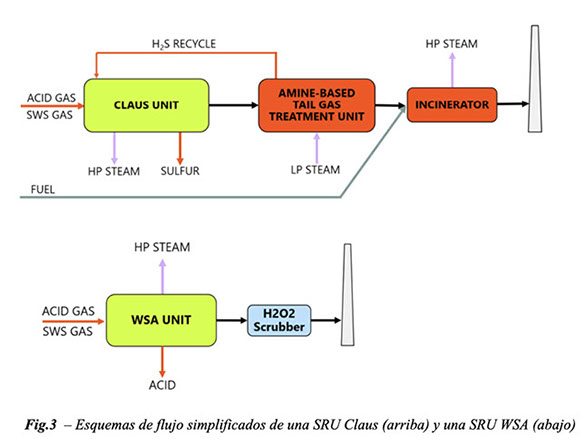
Para resaltar los beneficios de este enfoque, se realizó un estudio de caso comparando el desempeño ambiental del proceso WSA con el de un proceso Claus modificado y una configuración de TGTU basada en aminas. Ambos sistemas fueron diseñados para lograr una recuperación de azufre del 99,9%.
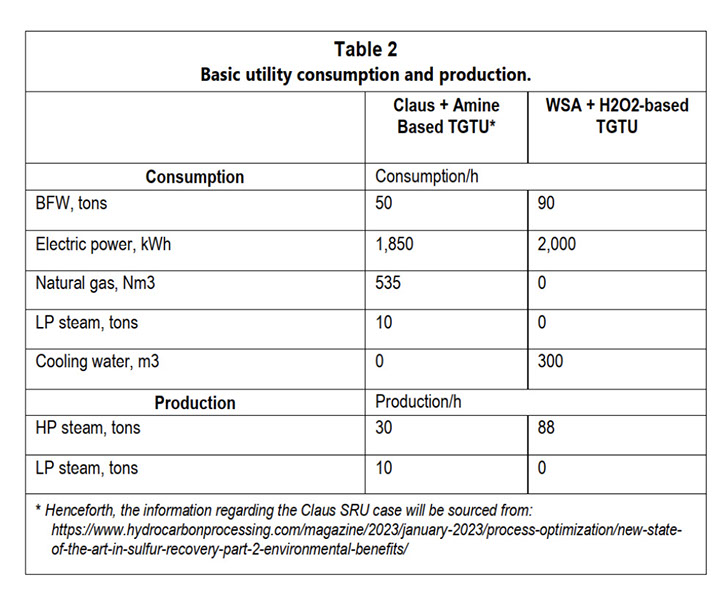
El estudio de caso se centró en unidades de recuperación de azufre (SRU) de una refinería de petróleo nueva (greenfield), procesando gas ácido de aminas con un 90% molar de H₂S y gases residuales de la despojadora de aguas ácidas (SWS), produciendo 270 toneladas por día (TPD) de azufre y 800 TPD de ácido sulfúrico. El análisis comparó las emisiones directas de CO₂ provenientes de los gases de combustión y las emisiones indirectas de CO₂ asociadas a la producción y consumo de servicios auxiliares.
Los datos de consumo y producción de servicios auxiliares para la unidad Claus y la WSA muestran diferencias significativas atribuibles a los distintos diseños de proceso y configuraciones de equipos. A continuación, se presenta un análisis detallado de estas diferencias:
2.1.1. Energía Eléctrica.
El proceso WSA tiene un consumo eléctrico mayor que el proceso Claus, principalmente debido al mayor caudal de gas y al uso de un condensador de ácido enfriado por aire. Las tasas de flujo volumétrico de gas en los procesos Claus y WSA difieren principalmente por los métodos de combustión empleados. El proceso Claus utiliza oxidación parcial, lo que da como resultado un volumen específico de gas. En cambio, el proceso WSA emplea combustión completa, lo que genera volúmenes de gas de proceso más elevados.
2.1.2. Gas Natural.
A diferencia del proceso Claus, que requiere el consumo de gas natural en el incinerador para eliminar los compuestos residuales de azufre, el proceso WSA no necesita combustible externo para la combustión. Si bien el incinerador garantiza el cumplimiento ambiental al evitar la emisión de contaminantes, al mismo tiempo contribuye al aumento de las emisiones de CO₂.
2.1.3. BFW (agua de alimentación de caldera) y Vapor.
Los reboilers de la TGTU requieren una cantidad considerable de vapor de baja presión, que supera la generación de vapor del proceso Claus. Por otro lado, el proceso WSA genera una gran cantidad de vapor de alta presión sobrecalentado sin necesidad de aporte de vapor de baja presión.
2.1.4. Agua de Enfriamiento.
El proceso WSA incorpora una etapa de enfriamiento para el ácido sulfúrico, utilizando agua de recirculación. Si bien la huella de carbono directa del suministro y tratamiento de agua para este proceso no fue cuantificada, probablemente sea mayor que la del proceso Claus debido al aumento en la demanda de agua. Sin embargo, el proceso WSA elimina la generación de aguas residuales y el uso de productos químicos, lo que podría compensar el impacto de carbono asociado al consumo de agua.
2.1.5. Conclusión sobre las diferencias
Estos hallazgos preliminares indican que el proceso WSA ofrece ventajas potenciales en términos de eficiencia energética y reducción de emisiones de carbono en comparación con el proceso Claus modificado. Sin embargo, es necesario realizar un análisis más completo, que incluya balances de energía y masa, para cuantificar plenamente el alcance de estos beneficios.
En la siguiente sección, profundizaremos en los resultados de los estudios de caso, examinando los datos de consumo energético y emisiones. Al comparar ambas tecnologías, podremos evaluar el impacto ambiental general de los dos procesos y su posible contribución a los objetivos de descarbonización de las refinerías.
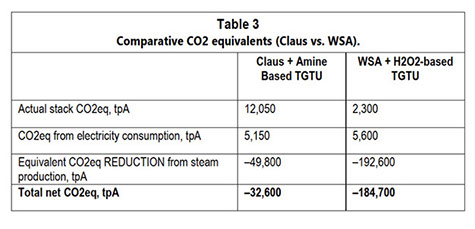
2.1.6 Emisiones de CO₂: un análisis comparativo
El proceso WSA logra una mayor eficiencia energética que los procesos Claus modificados al producir más vapor y consumir menos gas natural. Esto se traduce en menores emisiones de CO₂ en los gases de combustión, ya que la combustión de gas natural en el quemador WSA es mínima. El contenido de CO₂ en el gas ácido es bajo y no afecta significativamente las emisiones de la chimenea. Además, la alta concentración de H₂S proporciona una importante entrada de energía al quemador WSA, eliminando la necesidad de combustión de gas natural.
Para mantener la coherencia con estudios previos realizados por Topsoe y Worley Comprimo que comparan las unidades Claus y TopClaus⁵, este análisis asume que la electricidad es suministrada por la red nacional con una intensidad de carbono de 330 g CO₂eq/kWh. Además, para tener en cuenta el valor energético potencial del vapor exportado, se aplica un factor de emisión de CO₂ de 200 g CO₂eq/kWh, asumiendo una eficiencia de caldera del 85% y gas natural como combustible.
El ahorro significativo de emisiones de CO₂ logrado mediante la producción de vapor resalta la importancia estratégica de maximizar su utilización más allá de la propia SRU. Al sustituir el consumo de combustible en las calderas de la refinería, este recurso energético ofrece una vía directa para reducir las emisiones de GHG de Alcance 1.
(5) Hydrocarbon Processing magazine, December 2022, New state of the art in sulfur recovery, Part 1
Además, la posibilidad de alcanzar emisiones netas negativas de CO₂ posiciona a las refinerías para participar en programas de créditos de carbono. Estas iniciativas incentivan los esfuerzos de reducción de GHG y ofrecen oportunidades para compensar las emisiones de Alcance 2 mediante la generación de electricidad, especialmente cuando las emisiones directas de CO₂ provienen principalmente de calentadores de proceso y no de calderas.
El perfil individual de emisiones de GHG de cada refinería, sin duda, influirá en la selección de estrategias específicas de mitigación. Sin embargo, la solución descrita anteriormente proporciona a las refinerías una vía viable hacia la descarbonización sin comprometer la rentabilidad, y representa una alternativa atractiva frente a opciones más intensivas en capital de inversión, como la captura, utilización y almacenamiento de carbono.
2.2. Estudio de Caso 2
Varias refinerías han adoptado el proceso WSA como parte de su estrategia de recuperación de azufre, especialmente cuando sus unidades Claus existentes llegan al final de su vida útil y requieren ser reemplazadas. Estas refinerías han reconocido los beneficios del WSA en términos de eficiencia energética y desempeño financiero, lo que ha llevado a una transición gradual de Claus a WSA a medida que las unidades antiguas quedan obsoletas. Una de estas empresas es la Refinería del Caso 2, ubicada en el sur de Asia, que tiene una capacidad de procesamiento de aproximadamente 120.000 BPD y comenzó sus operaciones en la década de 1970. La refinería contaba con 4 trenes Claus en operación, con una capacidad total de procesamiento de 300 toneladas métricas por día (MTPD) de azufre elemental. Los trenes Claus estaban experimentando deterioro y presentaban problemas de confiabilidad, y en lugar de construir un tren adicional, la refinería optó por instalar una unidad WSA.
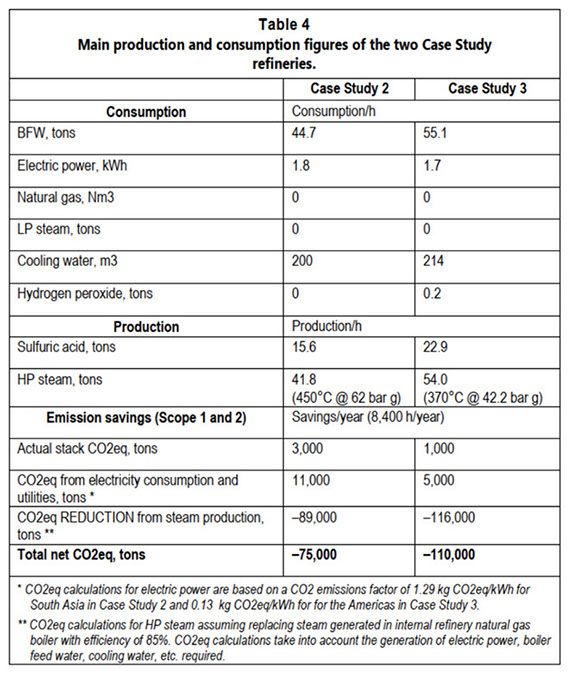
La unidad WSA en la Refinería del Caso 2 tiene una capacidad de procesamiento de 375 MTPD de ácido sulfúrico, equivalente a 123 MTPD de azufre, utilizando como alimentación gas ácido de la Unidad de Regeneración de Aminas (ARU) y gas de la SWS. La unidad emplea la tecnología de Doble Condensación de Topsoe, que se basa únicamente en la conversión catalítica de SO₂, eliminando la necesidad de una unidad de tratamiento de gases residuales y logrando una tasa de recuperación de azufre del 99,9%. El proceso no requiere productos químicos y no genera corrientes de desecho. La unidad opera utilizando calor generado internamente, sin necesidad de aporte adicional de calor, y exporta una cantidad significativa de vapor de alta presión sobrecalentado (450°C @ 62 barg). Las cifras completas de producción y consumo se presentan en la Tabla 4.
Tras la puesta en marcha en 2022, la refinería observó de inmediato mejoras en la eficiencia general. El ácido sulfúrico producido, al ser de calidad comercial, generó un flujo de ingresos constante debido a la fuerte demanda del mercado local, y el aumento en la capacidad de procesamiento confiable permitió que la refinería operara a máxima capacidad incluso cuando uno de los trenes Claus sufría una parada o requería mantenimiento. Además, la refinería experimentó una reducción significativa en el consumo de gas natural en su caldera principal, atribuida al vapor de alta presión sobrecalentado producido por la unidad WSA. Esta generación de vapor, libre de emisiones de CO₂ asociadas a la combustión de gas natural, permitió a la refinería declarar una reducción notable de CO₂ equivalente para toda la planta. La Refinería del Caso 2 ha reportado un ahorro de 23.700 MTPA de SRFT (Standard Refinery Fuel Tons). Utilizando los factores de emisión para la ubicación en el sur de Asia (factor de emisión de CO₂ de 1,29 kg CO₂eq/kWh, asumiendo una eficiencia de caldera del 85% y gas natural como combustible), la unidad WSA instalada contribuirá con una reducción de 75.000 MTPA de CO₂ equivalente, lo que ha llevado a la refinería a explorar la posibilidad de reemplazar líneas adicionales de unidades Claus por unidades WSA.
2.3. Estudio de Caso 3
Cuando una empresa decide construir una refinería nueva (greenfield) o realizar una reconstrucción completa de una refinería existente, tiene una oportunidad de oro para optar por las tecnologías más modernas, confiables y eficientes en términos energéticos disponibles. Esta oportunidad fue aprovechada por la Refinería del Caso 3, una empresa bien establecida en el procesamiento de crudo en América. Al reemplazar y expandir su refinería en su sitio principal, se dedicó un análisis exhaustivo a la selección de tecnologías, priorizando la generación de la mayor rentabilidad para la empresa, manteniendo un alto enfoque en la confiabilidad y el tiempo de operación, y considerando también la eficiencia energética. Estas consideraciones llevaron a la refinería a confiar toda la recuperación de azufre de la planta a un solo tren WSA. Contrariamente a la configuración típica de las unidades Claus, que cuentan con varios trenes en paralelo para asegurar la disponibilidad durante paradas, la tecnología WSA tiene un factor de operación comprobado tan alto que la refinería decidió tratar todos los gases ácidos de la ARU y los gases de la SWS en una sola unidad WSA, con una capacidad total de 560 MTPD de ácido sulfúrico, o su equivalente a 183 MTPD de azufre.
La Refinería del Caso 3 tenía como objetivo crear una instalación moderna y eficiente en términos energéticos que cumpliera con todas las regulaciones ambientales locales. Por ello, optaron por una unidad WSA de condensación simple con un depurador de gases residuales que utiliza peróxido de hidrógeno, logrando emisiones de SOx inferiores a 150 mg/Nm³ (@ 3%v O₂, seco). Al reciclar la corriente de purga de la unidad de gases residuales hacia el quemador, la unidad alcanzó una tasa total de recuperación de azufre superior al 99,94%. Aunque las principales motivaciones para instalar la WSA como SRU fueron la alta confiabilidad y el alto valor del producto (el ácido sulfúrico es claramente rentable en el mercado local), la refinería también se benefició de la producción adicional de energía proporcionada por el proceso WSA. La unidad WSA produce una cantidad significativa de vapor de alta presión sobrecalentado (370°C @ 42.2 bar g), lo que reduce el consumo de gas natural de la refinería en la caldera principal de generación de energía. Las principales cifras de producción y consumo de la unidad WSA de la Refinería del Caso 3 se presentan en la Tabla 4.
3. UN CAMINO HACIA EL FUTURO: DESCARBONIZACIÓN MEDIANTE LA ADOPCIÓN DE WSA
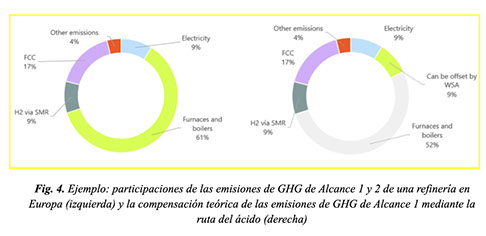
Las emisiones de GHG provenientes de hornos y calderas, así como de la electricidad en las refinerías de tipo hydroskimming, representan el 66.2% y el 26.5%, respectivamente, del total de emisiones de GHG⁶. Esto resalta la importante contribución de estos procesos a la huella de carbono del sector de refinación.
La refinería típica de nuestro ejemplo, que procesa 10 MTA de crudo y emite 2 Mt de CO₂ de Alcance 1 y 2, puede compensar aproximadamente el 1.5% de su huella total de carbono mediante la generación de vapor dentro del proceso Claus. Sin embargo, para acelerar los esfuerzos de descarbonización, las refinerías pueden asignar estratégicamente una parte de su corriente de gas ácido a la producción de ácido sulfúrico. Este cambio estratégico permite aprovechar el vapor de alta presión, reduciendo así la demanda de vapor de las calderas de la refinería y, en consecuencia, disminuyendo las emisiones directas de CO₂ de Alcance 1 provenientes de la chimenea.
(6) Global oil refining's contribution to greenhouse gas emissions from 2000 to 2021: The Innovation (cell.com)
Una transición completa de la producción de azufre a la producción de ácido dentro de esta refinería típica podría, en teoría, compensar hasta un 9% de sus emisiones totales de CO₂ al aprovechar la energía generada por el proceso WSA. La calidad del vapor de alta presión sobrecalentado producido por WSA también ofrece oportunidades para su integración con turbinas de vapor para la generación de electricidad. Esta integración puede generar valor adicional a través de programas de créditos de carbono o compensando las emisiones de CO₂ de Alcance 2, siempre que la refinería utilice la electricidad generada en lugar de comprarla de la red.
Explorar oportunidades para mejorar la eficiencia energética general, modernizar o reemplazar las unidades existentes basadas en Claus por unidades WSA representa una vía prometedora para acelerar los esfuerzos de descarbonización en una refinería. Una reducción gradual de la huella de carbono del 2-3% por cada línea Claus reemplazada por una unidad WSA ofrece un camino estratégico y financieramente viable para alcanzar el objetivo de descarbonización de las refinerías. Si bien la transición hacia la producción de ácido introduce nuevas consideraciones, los posibles beneficios de la diversificación de productos y la demanda global de ácido sulfúrico la convierten en una propuesta atractiva para las refinerías que buscan optimizar sus operaciones y su desempeño ambiental.
Conclusión
Descarbonizar la industria de refinación es esencial para cumplir con los objetivos globales de emisiones, y los procesos de recuperación de azufre pueden desempeñar un papel clave en este esfuerzo. Si bien el proceso Claus ha sido durante mucho tiempo el estándar de la industria, los crecientes requisitos ambientales y de eficiencia han impulsado la exploración de alternativas complementarias. La tecnología WSA surge como una solución prometedora, ya que permite una mayor recuperación de energía y reducciones significativas de emisiones de CO₂.
Los estudios de caso demuestran que la transición de Claus a WSA no solo mejora el desempeño ambiental, sino que también incrementa la confiabilidad operativa y genera nuevas fuentes de ingresos. Aunque el reemplazo completo de las unidades Claus no siempre sea factible, un cambio gradual hacia WSA ofrece un camino práctico y efectivo para la descarbonización de las refinerías. Adoptar la tecnología WSA permite a las refinerías reducir su huella de carbono y posicionarse mejor para un futuro sostenible.
1) Decarbonizing Chemicals and Refining - Pathways to Commercial Liftoff (energy.gov)
2) Global oil refining's contribution to greenhouse gas emissions from 2000 to 2021: The Innovation (cell.com)
3) Hydrocarbon Processing magazine, December 2022, New state of the art in sulfur recovery, Part 1




> SUMARIO DE NOTAS
TRANSICIÓN ENERGÉTICA. PRODUCCIÓN DE E-FUELS PARA LOS SECTORES DE AVIACIÓN Y MARÍTIMO
MODELIZACIÓN DE EMISIONES DE GHG EN LA PLANIFICACIÓN DE LA REFINERÍA
UN ENFOQUE PASO A PASO PARA REDUCIR LA HUELLA DE CO₂ A TRAVÉS DE UNIDADES SRU
IMPLEMENTACIÓN DE TECNOLOGÍA DE GEMELO DIGITAL COMO SISTEMA DE MANEJO DE LA ENERGÍA EN REFINERÍA CAMPANA
> Ver todas las notas


Instituto Argentino del Petróleo y del Gas
Maipú 639 (C1006ACG) - Tel: (54 11) 5277 IAPG (4274)
Buenos Aires - Argentina
> SECCIONES
> NUESTRAS REDES
Copyright © 2025, Instituto Argentino del Petróleo y del Gas,todos los derechos reservados