

-crop-u148576.jpg?crc=462165101)
NOTA DE TAPA
TRANSICIÓN ENERGÉTICA. PRODUCCIÓN DE
E-FUELS PARA LOS SECTORES DE AVIACIÓN Y MARÍTIMO
Por Chantiri Bárbara y Jaworski María Angélica (Y-TEC)
Introducción
Los e-fuels, o combustibles sintéticos renovables de origen no biológico (RFNBO, según la Unión Europea) se producen principalmente utilizando electricidad renovable como fuente de energía y podrían convertirse en la solución a futuro para la descarbonización de sectores del transporte difíciles de electrificar en el marco de la transición energética.
La aviación y el transporte marítimo se encuentran entre los modos de transporte más difíciles de descarbonizar. La alta densidad de energía de los combustibles fósiles que utilizan permite a los barcos y aviones viajar largas distancias sin la necesidad de repostar en ruta. Viajar largas distancias intercontinentales en aviones o embarcaciones eléctricas es imposible debido a la baja densidad de energía y el alto peso de las tecnologías de baterías existentes que ofrecen un alcance limitado.
Para hacer posible la descarbonización del transporte aéreo y marítimo se requieren combustibles bajos en carbono y de alta densidad energética.
Los e-fuels se producen principalmente utilizando electricidad como fuente de energía y podrían reducir significativamente las emisiones en estos sectores difíciles de descarbonizar.
Hay dos familias de e-fuels. La primera son los PTL (power to liquid) o PTG (power to gas) a base de carbono, como el e-jet o e-querosén y el e-metano. Se pueden hacer compatibles con los vehículos y la infraestructura existentes con modificaciones relativamente menores. Los beneficios en su uso aguas abajo contrastan con los desafíos en su producción aguas arriba.
Para que se consideren bajos en carbono, los e-fuels basados en carbono deben producirse con materias primas renovables, hidrógeno y carbono provenientes de la atmósfera o de fuentes biogénicas. Las materias primas de carbono alternativas pueden obtenerse de fuentes puntuales industriales, pero solo ofrecen un beneficio de descarbonización limitado y a corto plazo. Estos factores significan que otras formas de combustibles líquidos bajos en carbono, como los biocombustibles sostenibles, probablemente serán una solución más rentable durante la transición. Sin embargo, incluso los biocombustibles sostenibles tienen cuotas de mercado bajas en las industrias del transporte marítimo y la aviación. Los combustibles de aviación sostenibles, por ejemplo, solo representan el 0,3% del uso del combustible para aviación en la actualidad. Los biocombustibles sostenibles también se enfrentan a la demanda competitiva de muchos otros sectores y a la limitación a futuro en su materia prima.
La segunda familia de e-fuels son combustibles que no se basan en el carbono, como el hidrógeno y el amoníaco. Estos combustibles son relativamente fáciles de producir en comparación con los e-fuels a base de carbono y también más baratos. Sin embargo, son mucho más difíciles de manejar en uso e incompatibles con las tecnologías existentes de embarcaciones y aeronaves. Para convertirse en una opción viable, los combustibles no basados en carbono requieren un transporte y reabastecimiento complejos en infraestructura y necesitarán avances tecnológicos con respecto a los sistemas de propulsión y almacenamiento del combustible. Por todo esto es probable que su adopción sea lenta, ya que depende de la disponibilidad del combustible y la rotación de la flota de vehículos.
El hidrógeno requiere un transporte dedicado y tanques de combustible altamente especializados a bordo. El amoníaco evita algunas de estas desventajas y, por lo tanto, podría ser más adecuado como combustible para barcos. Los beneficios de las emisiones de CO2 que evita el uso del amoníaco podrían compensarse por completo con las emisiones de nitrógeno reactivo de su combustión. Evitar esto requiere tecnologías de postratamiento altamente efectivas y la minimización de emisiones fugitivas. El amoníaco también podría causar accidentes ambientales en caso, por ejemplo, de un derrame, por lo que se requieren estrictas pautas de seguridad.
Los aviones de hidrógeno deben cumplir requisitos muy estrictos de seguridad y rendimiento para convertirse en una opción viable. Los estudios de factibilidad sugieren que podrían servir para vuelos de corta a media distancia. Los fabricantes de aeronaves han anunciado planes para introducir aeronaves que utilicen esta tecnología en la década de 2030. Sin embargo, se necesita un desarrollo tecnológico adicional.
Hoy en día, la producción de e-fuels bajos en carbono aún no ha alcanzado una escala comercialmente significativa. Los costos son altos y la tecnología se encuentra en una etapa relativamente temprana. Para reemplazar cantidades significativas del uso de combustibles fósiles en el transporte marítimo y la aviación, los volúmenes de producción deberán aumentar rápidamente y esto solo sucederá con el apoyo específico de los gobiernos. La generación de electricidad renovable debe aumentar para mantenerse al día con la demanda de los nuevos proyectos de producción de combustibles sustentables. Las tecnologías de electrolizadores y captura de carbono deben avanzar para reducir los costos y permitir fuentes genuinamente renovables de materias primas de carbono a partir de la captura directa del aire o fuentes biogénicas de CO2.
Se necesitará al menos una década para lograr un nivel significativo de uso de e-fuels. Incluso eso dependerá de un sólido apoyo político para reducir la brecha de precios con los combustibles fósiles convencionales. Es probable que los e-fuels sigan siendo un recurso escaso a mediano plazo, dados los plazos necesarios para ampliar la capacidad de producción. Mientras tanto, los gobiernos y las empresas no deben descuidar las iniciativas para reducir los viajes evitables, mejorar la eficiencia energética de los buques y aeronaves y cambiar la demanda de transporte a modos más eficientes desde el punto de vista energético.
Desarrollo
1- Mercado y Regulaciones
1.1- Regulaciones sector aéreo
Muchos gobiernos han lanzado programas para promover el uso de combustibles sustentables. Estas iniciativas están impulsando la expansión del mercado de e-querosén e hidrógeno. Sin embargo, se espera que la cuota de mercado del e-querosén siga siendo muy reducida en el corto plazo. Los marcos de políticas para promover combustibles alternativos y tecnologías eficientes en la aviación tienden a ser menos estrictos que otros modos de transporte. La ICAO (International Civil Aviation Organization), cuyos países miembros son Alemania, Australia, Brasil, Canadá, China, Estados Unidos, Rusia, Francia, Italia, Japón y Reino Unido, es responsable de la reglamentación de la aviación internacional, incluidas las cuestiones ambientales y los objetivos del sector. En 2010, los estados miembros de la ICAO adoptaron los objetivos de lograr mejoras promedio en la eficiencia del combustible del 2 % por año entre 2020 y 2050 y un crecimiento del sector neutral en carbono entre 2020 y 2040. La 41.ª Asamblea de la ICAO, celebrada en septiembre-octubre de 2022, adoptó una meta global a la que se aspira a largo plazo para que la aviación internacional alcance emisiones netas de CO₂ cero para 2050. La misma reconoce al SAF (sustainable aviation fuel) como una medida esencial para la reducción de emisiones en el sector.
El SAF es un combustible sustentable de aviación que reduce las emisiones de GEI (gases de efecto invernadero) en al menos un 70% respecto de las emisiones que genera un combustible de aviación fósil convencional, según la ICAO.
Los instrumentos de la ICAO para lograr un crecimiento neutro en carbono a partir de 2020 son: mejoras operativas, tecnología de aeronaves, despliegue de bioenergía SAF y una medida basada en el mercado denominada Plan de reducción y compensación de carbono para la aviación internacional (CORSIA).
CORSIA: Las aerolíneas en los mercados que participan en CORSIA pueden compensar el crecimiento de las emisiones por encima del umbral comprando créditos o compensaciones de carbono negociables o implementando combustibles elegibles para CORSIA con baja intensidad de carbono. CORSIA fue diseñado para implementarse en fases, con un período piloto (2021-23), una primera fase (2024-26) no obligatoria y una segunda fase (2027-2035) que será obligatoria para los países con mayor % de emisiones de GEI. Argentina no tendrá obligatoriedad ya que sus emisiones están por debajo de lo requerido según el plan CORSIA.
La Unión Europea (UE) es el primer gran mercado de aviación con una elaborada estrategia SAF que promueve explícitamente los e-fuels. La propuesta de política de aviación de ReFuelEU, publicada por la Comisión Europea en 2021, prevé un objetivo de combinación de SAF que aumenta gradualmente. Este incluye objetivos secundarios para los e-fuels que se aplicarían a los vuelos nacionales e internacionales que salen de los aeropuertos de la UE.
El mandato blending de SAF entró en vigencia el 1 de enero del corriente año 2025, especificando una cuota del 2 % de SAF de todo el combustible de aviación suministrado en todos los aeropuertos dentro de la UE, aumentando al 6 % en 2030 y alcanzando el 70 % en 2050. Los combustibles sintéticos tienen cuotas asignadas dentro del objetivo general de mezcla SAF, comenzando desde un 1,2% para 2030 y alcanzando el 35% para 2050.
En la actualidad, mayo 2025, la producción de SAF representa aproximadamente el 0,3% del consumo global de combustible de aviación, mostrando una brecha significativa con el objetivo de alcanzar el 2% para este año. Esto marca un desafío muy grande para todos los productores de SAF y para todas las aerolíneas si desean cumplir con el objetivo sin tener que pagar penalidades. Es por esto que a principios de año, la Comunidad Europea decidió dar flexibilidad a esta normativa, permitiendo a todos los operadores y aerolíneas promediar sus cargas de SAF dentro de todos los aeropuertos de la Unión Europea. Estará vigente desde 2025 hasta principios de 2035 y tiene como objetivo que las aerolíneas y empresas proveedoras de combustible, no tengan que afrontar el pago de penalidades, y promover así las inversiones necesarias para poder tener el combustible en todos los aeropuertos de la U.E. a futuro y poder así cumplir con las cuotas de SAF que se van requiriendo en los próximos 30 años.
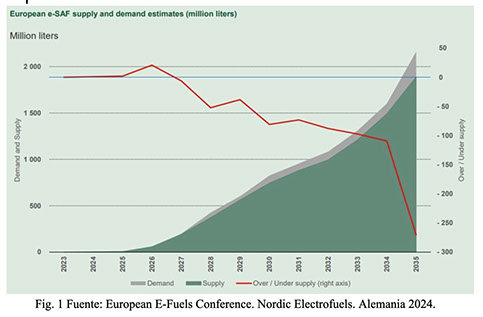
A continuación, se muestran en el gráfico adjunto la proyección de la demanda de SAF vs la oferta teniendo en cuenta todos los proyectos que se encuentran en diferentes etapas de desarrollo para la U.E. (Fig. 1)
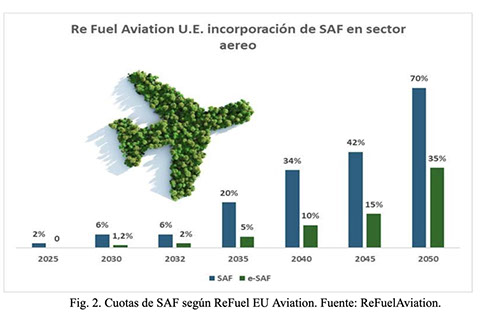
En la Fig. 2 que se muestra a continuación es posible observar las cuotas de SAF que estarán obligadas las aerolíneas en la U.E. a incorporar a partir de 2025, aumentando dichas cuotas cada 5 años.
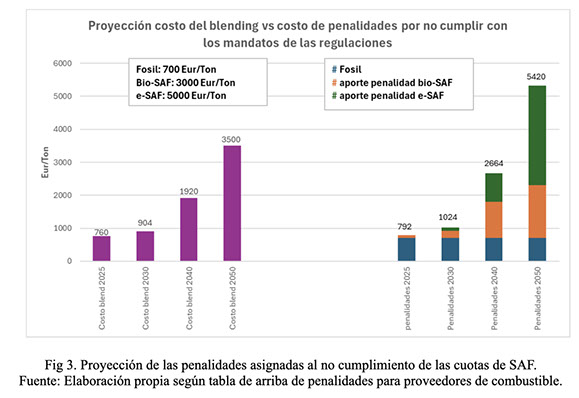
También a continuación en el siguiente gráfico puede verse un ejemplo de la proyección de las penalidades que se asignarán al no cumplimiento de las cuotas de SAF definidas para la UE según las regulaciones (Fig. 3, https://www.now-gmbh.de/wp-content/uploads/2023/11/NOW-Factsheet_ReFuelEU-Aviation-Regulation.pdf).
Cabe destacar que, para el siguiente gráfico, se utilizó un precio promedio actual de cada tipo de combustible y se proyectaron tanto los costos del blending como las penalidades, con el único propósito de ilustrar el impacto de estas penalidades en comparación con el costo de cumplir con las cuotas anuales de SAF
1.2- Regulaciones sector marítimo
El sector marítimo se enfrenta al desafío de reducir sus emisiones GEI y cumplir con las metas establecidas por la Organización Marítima Internacional (OMI). La adopción de tecnologías y combustibles energéticamente eficientes se presenta como una solución clave para acelerar la descarbonización y garantizar un transporte marítimo sostenible.
La organización ha propuesto adoptar en 2018 dos medidas obligatorias para reducir las emisiones de gases de efecto invernadero procedentes de buques, en virtud del tratado para prevenir la contaminación del mar (Convenio MARPOL): el Índice de eficiencia energética del proyecto (EEDI) de carácter obligatorio para los buques nuevos y el Plan de gestión de la eficiencia energética del buque (SEEMP).
En 2018, la OMI adoptó la Estrategia inicial para reducir los GEI, definiendo así una visión que demuestra el compromiso de la organización de reducir las emisiones de GEI procedentes del transporte marítimo internacional. Dicha estrategia fue reversionada en junio de 2023.
La OMI también está ejecutando proyectos mundiales de cooperación técnica para reforzar la capacidad de los Estados Miembros, especialmente los países en desarrollo, con vistas a implantar y apoyar la eficiencia energética del sector.
El MEPC 74 (Comité de Protección del Medio Marino, mayo 2019) adoptó la resolución por la que invita a los Estados Miembros a fomentar la cooperación voluntaria entre los sectores portuarios y del transporte marítimo para contribuir a la reducción de las emisiones de GEI procedentes de los buques.
La Alianza Global de la Industria (GIA, Global Industry Alliance) ha apoyado al sector marítimo de bajo carbono que opera bajo los auspicios del proyecto GloMEEP (Global Maritime Energy Efficiency Partnerships) de la OMI y ha reconocido el papel clave de los puertos en la descarbonización del transporte marítimo. En particular, la operación de barcos justo a tiempo (JIT, Just in time) tiene el potencial de reducir las emisiones. La GIA ha estado acumulando experiencia de puertos que han implantado JIT con éxito y sin éxito, ha estado analizando barreras; y ha estado estudiando medidas concretas para eliminar estas barreras a la adopción a gran escala de JIT.
En junio de 2023 se revisó la estrategia inicial de la OMI, con alta aceptación de todos sus miembros.
Los niveles de ambición que rigen la Estrategia de GEI de la OMI para 2023 son los siguientes:
1- Disminución de la intensidad de carbono del buque mediante una mejora de la eficiencia energética de los buques nuevos.
2- Disminución de la intensidad de carbono del transporte marítimo internacional, reduciendo las emisiones de CO2 por trabajo de transporte, como promedio en el transporte marítimo internacional, en al menos un 40 % para 2030, en comparación con 2008.
3- Adopción de tecnologías, combustibles y/o fuentes de energía con emisiones de GEI nulas o casi nulas.
4- Reducir las emisiones de GEI del transporte marítimo internacional para llegar a cero neto (net zero) en 2050, considerando las diferentes circunstancias nacionales, mientras se realizan esfuerzos para eliminarlas gradualmente como se exige en la Visión de conformidad con el objetivo de temperatura a largo plazo establecido en el artículo 2 del Acuerdo de París.
Los puntos de control indicativos para alcanzar cero emisiones netas de GEI del transporte marítimo internacional son:
1- Reducir las emisiones anuales totales de GEI del transporte marítimo internacional en al menos un 20 %, esforzándose por alcanzar el 30 %, para 2030, en comparación con 2008 (el nivel de ambición es llegar a un 40% de reducción para 2030).
2- Reducir las emisiones anuales totales de GEI del transporte marítimo internacional en al menos un 70%, esforzándose por alcanzar el 80%, para 2040, en comparación con 2008.
Próximos pasos acordados:
La Estrategia 2023 establece un cronograma para la adopción de las medidas candidatas para la reducción de GEI y la adopción de la Estrategia de GEI de la OMI actualizada para 2028 (año en el que se volverá a revisar) sobre la reducción de las emisiones de GEI de los buques.
En paralelo y concordancia a la iniciativa de la OMI, la Unión Europea definió un paquete de medidas claves para la descarbonización de los diferentes sectores, este paquete de regulaciones es el “Fit for 55”, donde se encuentra la FuelEU Maritime. La misma es una iniciativa clave dentro del paquete legislativo “Fit for 55”, que busca reducir las emisiones netas de gases de efecto invernadero (GEI) en al menos un 55 % para 2030, en comparación con los niveles de 1990. Esta regulación se centra en descarbonizar el sector marítimo mediante la promoción de combustibles renovables y de baja emisión de carbono.
Objetivos del FuelEU Maritime:
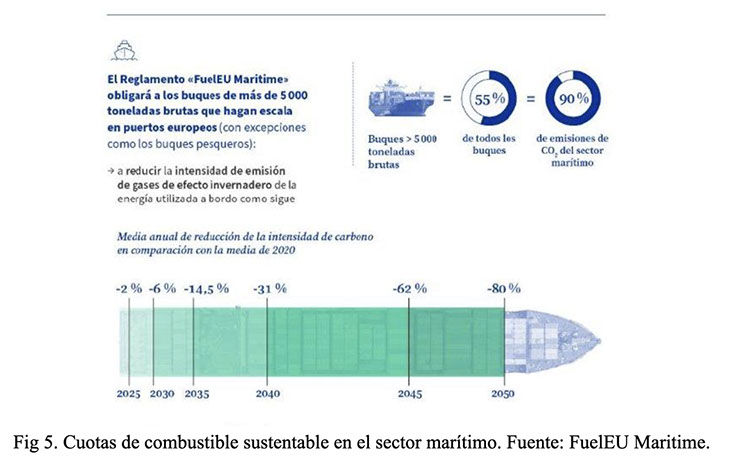
El principal objetivo del FuelEU Maritime es disminuir la intensidad de GEI de la energía utilizada a bordo de los buques que operan en la UE, promoviendo el uso de combustibles renovables y de baja emisión de carbono. La regulación establece una incorporación progresiva de combustible sustentables en los buques de más de 5000 toneladas, comenzando con un 2 % en 2025 y alcanzando hasta un 80 % en 2050.
Al igual que para el sector aviación, con la ReFuel Aviation, la Comunidad Europea aprobó a principios del corriente año 2025 flexibilizaciones en la FuelEU Maritime.
Para este 2025 se propone la incorporación de 2% de combustible sustentable, según la regulación original, un desafío importante, teniendo en cuenta que como para el sector aviación, el combustible sustentable no se encuentra distribuido de manera homogénea en la Unión Europea, su costo es mucho mayor que el del combustible fósil tradicional, y muchos puertos no cuentan con la infraestructura necesaria para su abastecimiento. Teniendo en cuenta estas barreras, se flexibilizó la incorporación de combustible sostenible, a través del "pooling", el cual permite promediar entre todos los buques de una flota de una misma empresa de transporte marítimo, este 2% de incorporación de combustible sustentable.
Otras acciones que la Fuel EU Maritime definió es la incorporación en todos los puertos de OPS, suministro eléctrico desde tierra, a partir de 2030. Esto permitirá a los buques apagar sus motores mientras estén parados en puerto sin emitir y sin dejar de estar energizados.
Corredores verdes, proyección a futuro:
Un corredor de navegación verde es una ruta de navegación entre dos o más centros portuarios importantes, en la que se despliegan barcos con cero emisiones de carbono y otros programas de reducción de emisiones, y las reducciones de emisiones se miden y habilitan a través de acciones y políticas públicas y privadas. La creación de Corredores Verdes ofrece la oportunidad de acelerar la fase emergente de la transición del transporte marítimo.
Hitos que están marcando el rumbo. Acciones concretas:
• El buque propulsado por metanol Stena Germanica, fue el primer no petrolero del mundo, en ser alimentado con metanol de barco a barco (ship-to-ship). La primera operación de bunkering de metanol del mundo se llevó a cabo en el puerto de Gotemburgo, Suecia durante enero de 2023.
• El primer buque portacontenedores verde alimentado con metanol, propiedad de A.P. Moller-Maersk, zarpó de Corea del Sur en julio 2023.
Se ha determinado que los barcos impulsados por metanol con opciones de combustible dual cuestan entre un 10% y un 12% más que los barcos convencionales, pero la diferencia de precio debería volverse insignificante a largo plazo una vez que los desarrolladores logren economías de escala.
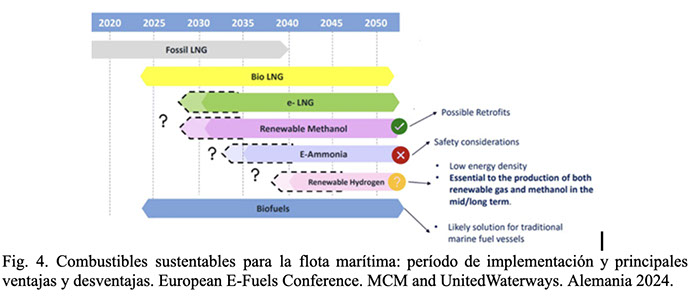
A continuación, en la Fig. 4, se observa un gráfico con los posibles combustibles sustentables que pueden usarse en la flota marítima para reducir su huella la carbono. En el mismo se incluyen los años en los cuales se promoverá su uso y las ventajas/desventajas de uso.
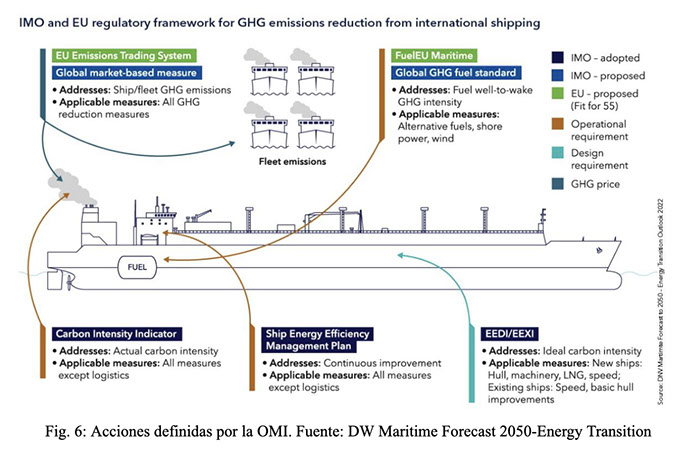
En las Fig. 5 y 6 pueden verse las cuotas de combustible sustentable marítimo a incorporar a partir de 2025 para alcanzar paulatinamente la reducción de emisiones de CO2 y lograr el Net Zero en 2050 según Fuel EU Maritime. (Fig. 5) y según diversas normas internacionales (Fig. 6).
2- Sustentabilidad
En este apartado se analizarán los requisitos de sustentabilidad que se están visualizando para el SAF en aviación o para el e-metanol en el transporte marítimo, criterios sobre fuentes aceptadas de producción de H2 y CO2 y criterios como huella de carbono total incluyendo emisiones en los procesos de producción.
La sostenibilidad ambiental de SAF debe verificarse a través de un análisis de sostenibilidad. Si el análisis considera que el combustible cumple con los requisitos, los lotes de este combustible deben ir acompañados de la documentación adecuada, a la que se hace referencia en un "certificado de sostenibilidad" (CoS, Certificate of Sustainability), hasta el destino final. Por lo general, es emitido por una organización acreditada que certifica que SAF de un origen específico y producido utilizando una vía de procesamiento específica cumple con los criterios de un estándar de sostenibilidad dado.
El simple uso de SAF no necesariamente reduce las emisiones totales de carbono; un SAF debe demostrar una reducción neta de carbono a través de un análisis del ciclo de vida (LCA), que es un elemento esencial de la certificación de sostenibilidad en al menos un 70% respecto del combustible fósil.
La evaluación del ciclo de vida (LCA) de un e-fuel es un enfoque establecido para evaluar y comparar el impacto ambiental a lo largo del ciclo de vida de un producto o proceso. Se puede utilizar para determinar si el cambio, por ejemplo, de un combustible fósil a un e-fuel estaba justificado por razones ambientales.
Hay múltiples criterios que se tienen en cuenta al determinar la sostenibilidad de un combustible. Algunas métricas típicas de sostenibilidad son las siguientes:
o Emisiones de carbono del ciclo de vida
o Cambio directo e indirecto del uso de la tierra
o Categorías de tierras autorizadas
o Consideraciones sobre el agua, el aire y el suelo
o Gestión de fertilizantes y plaguicidas
o Gestión de residuos
o Controles de especies invasoras
Las fuentes de dióxido de carbono que pueden ser utilizadas para la producción de e-fuels pueden ser: fuentes industriales como plantas de energía y fábricas, fuentes geológicas, fuentes biogénicas como plantas de biogás, bioetanol o quema de biomasa o bien capturado directamente del aire (DAC). Sin embargo, para que un combustible pueda ser certificado como sostenible, la fuente de CO2 de origen es fundamental. A continuación, un gráfico donde puede verse una línea de tiempo y las diferentes fuentes de CO2 que aplican para la certificación de un combustible. (Fig. 7):
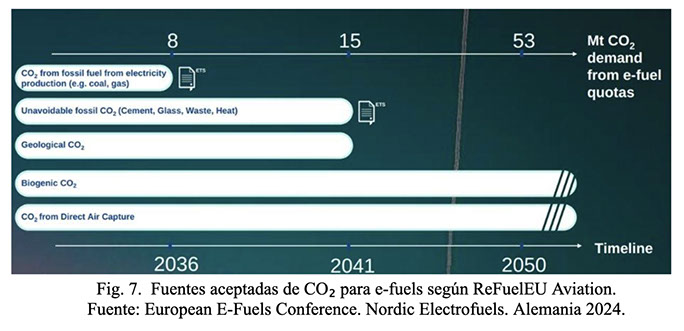
Como puede observarse en la Fig. 7, las fuentes aceptadas de CO₂ de origen para el período actual y hasta 2050, e incluso más allá son las biogénicas y la captura directa del aire. Otras fuentes presentan restricciones temporales que comprometen su elegibilidad para la certificación de combustibles sostenibles en el mediano y largo plazo. Esta delimitación responde a los criterios establecidos por el paquete regulatorio Fit for 55 de la Unión Europea, particularmente en el marco de la iniciativa ReFuelEU Aviation, que establece requisitos estrictos sobre el origen del carbono utilizado en la producción de combustibles sostenibles para la aviación.
Otro aspecto importante para determinar la sustentabilidad de un combustible es poder garantizar que cualquier generación de electricidad renovable utilizada sea "adicional" y no la reclame otro sector de la economía. Tener "criterios de adicionalidad" estrictos es vital para garantizar que se instale capacidad de generación de electricidad renovable dedicada para producir e-fuels.
A continuación, se muestra una matriz comparativa de los diferentes tipos de combustibles y sus aspectos de sustentabilidad (Fig. 8):
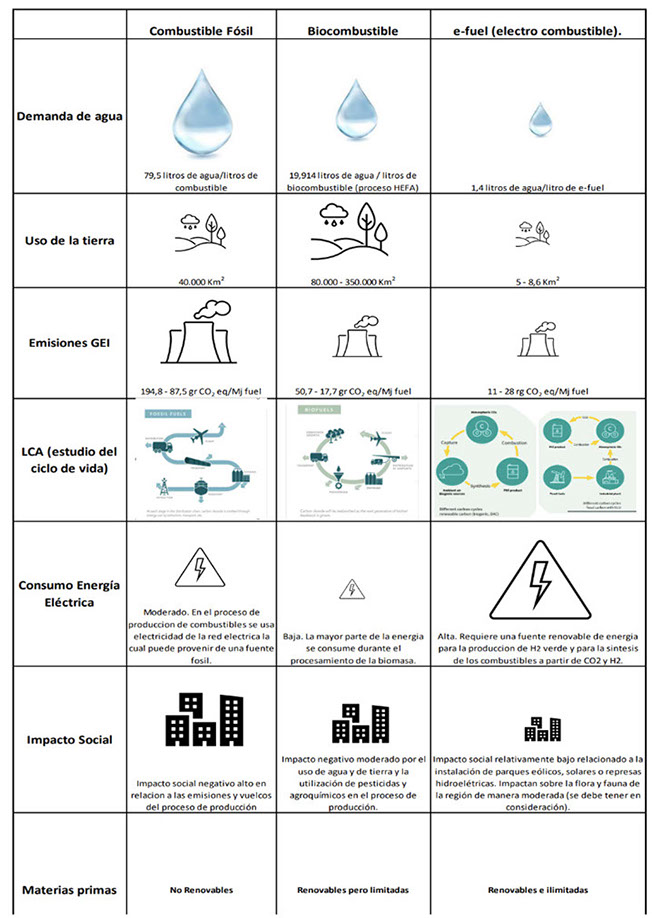
Fig. 8. Matriz de sustentabilidad comparativa entre distintos tipos de combustible (elaboración propia)
Los criterios de sustentabilidad para los combustibles bio y sintéticos de origen no biológico son:
• Emisiones GEI: las emisiones totales de los combustibles se expresan como la suma de componentes diferentes:
1. Emisiones procedentes de la extracción o cultivo de materias primas.
2. Emisiones anualizadas derivadas de los cambios en las reservas de carbono causados por el cambio en el uso de la tierra.
3. Emisiones procedentes de la transformación.
4. Emisiones procedentes del transporte y la distribución.
5. Emisiones procedentes del combustible en uso.
6. Reducción de las emisiones derivadas de la acumulación de carbono en el suelo mediante la mejora de la gestión agrícola.
7. Reducción de las emisiones derivadas de la captura y el almacenamiento geológico de carbono.
8. Ahorro de emisiones por exceso de electricidad procedente de la cogeneración.
• Demanda de agua. La demanda de agua para los e-fuels como el e-queroseno es de alrededor de 1,4 litros de agua por litro de combustible lo cual es varios órdenes de magnitud más bajo en comparación con las demandas de agua para la producción de biocombustibles y para la produccion de combustibles fósiles.
• Uso de la tierra: La disponibilidad de tierras es un indicador clave a la hora de evaluar el rendimiento comparativo de la sostenibilidad de los combustibles alternativos.
Existen dos conceptos para el cálculo de la demanda de superficie, la demanda bruta y la demanda neta de superficie de tierra.
La superficie bruta del terreno es relevante, para el cálculo de cuánta superficie se necesita en total para producir una cantidad determinada de combustible. Por ejemplo, en el caso de energía eólica, considera la distancia que debe haber entre las turbinas de un molino para evitar la sombra.
La superficie neta del terreno es relevante para la cuestión de cuánta tierra está ocupada por la instalación y no puede utilizarse para otros fines.
El rendimiento por área de combustible específico para la generación de energía renovable para los combustibles sintéticos es generalmente alto y superior a los rendimientos logrados con los biocombustibles.
• Eficiencia y uso de la energía eléctrica: Las directivas de la UE en lo referente a la generación y uso de energía renovable para la producción de e-fuels son más estrictas que para los combustibles de origen fósil y bio. La energía eléctrica es el principal insumo para la fabricación de combustibles sintéticos, en particular para la producción de H2 verde a partir de agua (proveniente de lagos, subterránea, de mar). Por lo tanto, el origen de la electricidad (renovable) y su integración en el sistema eléctrico son factores decisivos para determinar cumplir con las normativas de la UE. Dos características son de vital importancia: la renovabilidad y la adicionalidad.
➢ Renovabilidad. Para que los productos y procesos de combustibles sintéticos se consideren sostenibles, deben ser libres de combustibles fósiles y producidos con electricidad procedente de fuentes renovables, como la energía eólica, solar, hidráulica o geotérmica.
➢ Adicionalidad. La energía utilizada para la producción de combustibles sintéticos debe provenir de capacidad renovable adicional dedicada explícitamente a la producción de los mismos. De lo contrario, la producción de combustibles sintéticos basada en energías renovables conduciría, a un aumento en el uso de energía de origen fósil en otros segmentos del mercado.
⮚ Garantías de origen. Rastreo de la electricidad renovable desde su punto de generación hasta su uso final.
• Impacto social: Las refinerías generan importantes impactos ambientales y sociales, especialmente a través de emisiones atmosféricas, residuos sólidos y efluentes líquidos que contienen hidrocarburos, materia orgánica y metales pesados. En cuanto a los biocombustibles utilizados en el transporte, presentan ciertas desventajas ambientales, como el uso intensivo de fertilizantes y pesticidas que contribuyen a la emisión de óxidos de nitrógeno (NOx) y a la contaminación del agua. Además, su producción puede implicar un cambio en el uso del suelo, desplazando cultivos alimentarios, y requiere grandes volúmenes de agua para el riego. Por otro lado, los combustibles sintéticos, cuya producción depende de electricidad generada a partir de fuentes renovables, requieren una planificación cuidadosa de la infraestructura. Esta planificación debe considerar políticas de participación ciudadana, especialmente de las comunidades locales que puedan verse afectadas por los proyectos.
• Materias primas para e-fuels: Para la producción de combustibles sintéticos líquidos, se emplean carbono, hidrogeno y energía renovable como materias primas. Son materias primas renovables e ilimitadas.
A partir de la matriz es posible observar que los e-fuels, o combustibles sintéticos renovables de origen no biológico, son los que se presentan como más sustentables: las emisiones de GEI son menores, y el LCA es más sustentable que el resto de los combustibles evaluados (fósil y de origen biológico), adicionalmente, cuentan con una demanda de agua menor que el resto de los combustibles, tienen un uso menor de la tierra, el impacto social es menor, y las materias primas para su producción al igual que la energía son de origen renovable. Sin embargo, en estos combustibles la demanda de energía eléctrica es superior a los otros combustibles y debe ser generada y usada en el momento de la producción de los mismos.
Como conclusión los e-fuels presentan claras ventajas en sostenibilidad: generan menores emisiones de GEI, requieren menos agua y tierra, y utilizan materias primas renovables. Además, su impacto social es reducido en comparación con los combustibles fósiles y bio, aunque demandan una alta cantidad de energía eléctrica renovable y el costo de su producción es mayor que los otros dos.
3- Tecnologías de síntesis de e-fuels
Los combustibles líquidos sintéticos se han fabricado durante muchas décadas a través de a) la síntesis de metanol y b) el proceso Fischer-Tropsch, ambos utilizando fuentes fósiles de carbono. Para ambos procesos, el punto de partida es la conversión del combustible fósil (carbón, petróleo o gas natural) en gas de síntesis, que es una mezcla de monóxido de carbono, dióxido de carbono e hidrógeno.
3.1- Proceso de producción de metanol y su posterior conversión a combustibles sintéticos líquidos:
El metanol tradicionalmente se produce haciendo reaccionar gas de síntesis (H2 y CO) a una presión y temperatura relativamente altas utilizando un catalizador de cobre. Luego, el metanol se puede convertir en combustible líquido sintético mediante el empleo de catalizadores para formar alquenos, un proceso que actualmente se opera comercialmente, y los productos se pueden usar como precursores de combustibles líquidos sintéticos como gasolina (procesos MtG) o jet para aviación (Proceso MtJ).
La tecnología para la etapa de síntesis de e-metanol empleando CO2 y H2 es muy similar a la de la producción de metanol a partir de gas de síntesis a base de gas natural origen fósil. El catalizador tradicional de CuO/ZnO/Al2O3 utilizado solo tiene que modificarse ligeramente para adaptarse a la generación de mayores cantidades de agua durante la síntesis de e-metanol. La reacción se realiza a temperaturas entre 200 °C y 300 °C y presiones de 50-100 bar. También se están desarrollando catalizadores capaces de funcionar en condiciones más suaves de reacción.
El metanol es un producto almacenable y transportable, y también se puede utilizar directamente como combustible o como mezcla de combustibles. Una desventaja del metanol como combustible o para aplicaciones de transporte es su baja densidad energética en comparación con la gasolina, el diésel o el querosén.
A continuación, la reacción de síntesis del metanol y propiedades del producto, Fig. 9:
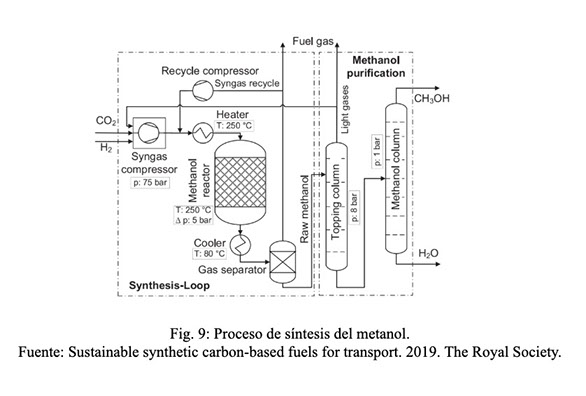
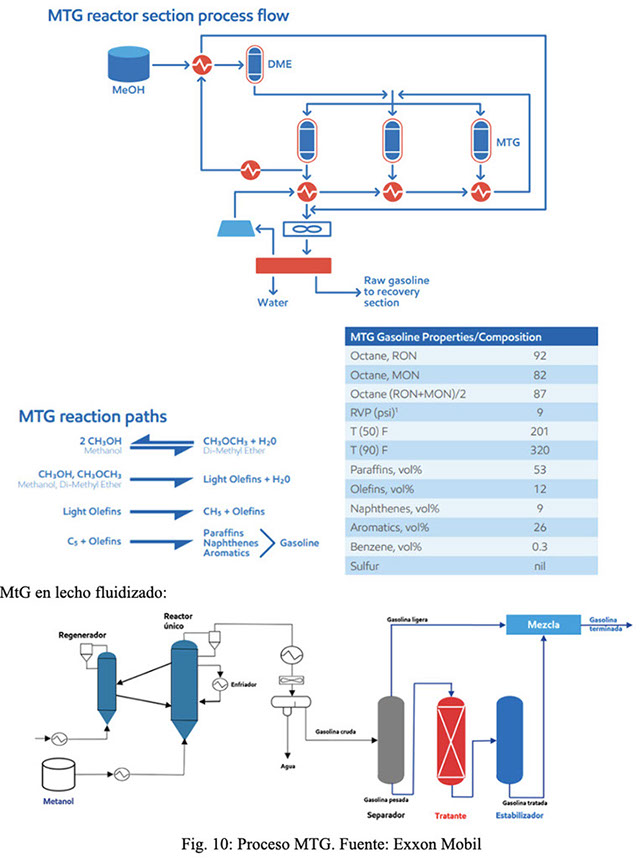
A partir del metanol se han desarrollado tecnologías, desde la desarrollada en los años ´70 por parte de Exxon Mobil, MtG (Methanol to Gasoline) en lecho fijo, luego modificada y patentada por parte del mismo tecnólogo en lecho fluidizado. A continuación, una imagen sobre el proceso MtG por parte de Exxon Mobil, y la estequiometría de las reacciones que se producen, Fig 10:
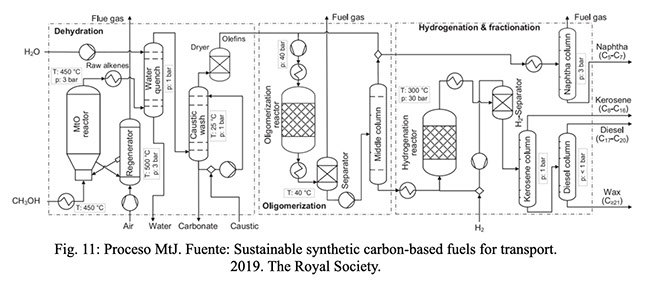
Por otro lado, en vistas de las exigencias en el sector aéreo se ha desarrollado por parte de varios tecnólogos, el proceso MtJ (Methanol to jet), para producción de jet sintético. En la fig 11 puede verse el proceso MtJ: El mismo consta de varias etapas, en la primera etapa el metanol sintetizado y purificado ingresa en un reactor MTO (Methanol to olefins), para generar olefinas livianas, este proceso utiliza catalizador del tipo Zeolítico. Posteriormente se ingresan dichas olefinas en un reactor donde se produce la oligomerización, generando olefinas de cadena larga (C8 a C16), longitud del querosén o jet sintético. Luego estas olefinas de cadenas más largas pasan a un proceso de hidrogenación, donde las olefinas se convierten en parafinas de cadenas de longitud del jet. Así se realiza un upgrading del producto final, y se obtiene finalmente el jet sintético para aviación.
3.2.- Proceso de producción de combustibles sintéticos líquidos Fisher-Tropsch:
El proceso de síntesis Fischer-Tropsch produce una amplia variedad de hidrocarburos lineales (saturados e insaturados), con números de carbonos que rondan entre 1 a 44, conociéndose como crudo FT, crudo sintético o “syncrude”. Este proceso parte de gas de síntesis: H2 y CO. Para obtener el gas de síntesis, previamente se debe pasar por un proceso previo de reacción denominado RWGS (Reverse Water Gas Shift), en este proceso ingresan H2 y CO2, y a partir de un proceso catalítico a elevadas temperaturas (entre 800 y 1000 °C), se obtiene el gas de síntesis. Este gas de síntesis sirve como alimentación al reactor del proceso catalítico Fisher-Tropsch.
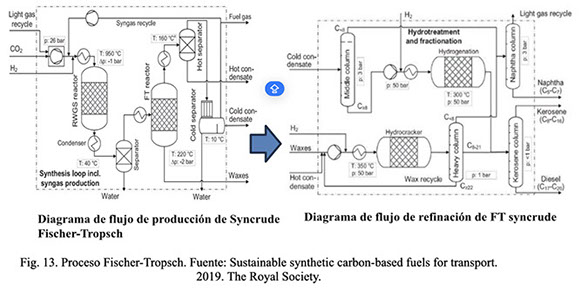
La distribución de hidrocarburos obtenidos en el crudo Fisher-Tropsch dependerá del catalizador y las condiciones de reacción (Fig. 3). El producto final debe ser refinado mediante procesos de refino convencionales como hidrocraqueo, reformado, isomerización, alquilación, destilación, entre otros.
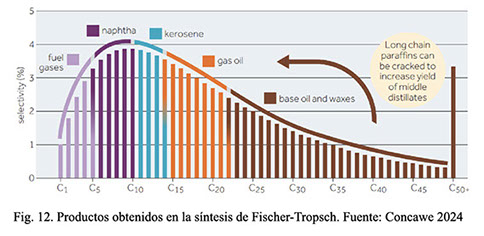
Además de alcanos, se forman algunos alquenos, alcoholes y ácidos carboxílicos. Para todos los productos, la relación molar del gas de síntesis es de aproximadamente 2 mol H2 a 1 mol CO. Los distintos productos generados por Fischer-Tropsch están influenciados predominantemente por la temperatura y el catalizador, lo que en promedio da como resultado hidrocarburos más ligeros para altas temperaturas (320-350 °C) e hidrocarburos más pesados para bajas temperaturas (190-250 °C).
A continuación, se muestran las ecuaciones que resumen la obtención de petróleo sintético a través de Fischer-Tropsch:
Reverse Water-Gas Shift (RWGS) 𝑪𝑶𝟐+𝑯𝟐→𝑪𝑶+𝑯𝟐𝑶
Fischer-Tropsch 𝟏𝟐𝑪𝑶+𝟐𝟓𝑯𝟐→𝑪𝟏𝟐𝑯𝟐𝟔+𝟏𝟐𝑯𝟐𝑶
Reacción global simplificada 𝒏𝑪𝑶+(𝟐𝒏+𝟏)𝑯𝟐→𝑯(𝑪𝑯𝟐)𝑯+𝟐𝑯𝟐𝑶 Δ𝑯𝟎=−𝟏𝟓𝟐𝑲𝑱𝒎⁄𝒐𝒍
En la fig. 13 se puede ver el proceso Fisher-Tropsch y sus etapas:
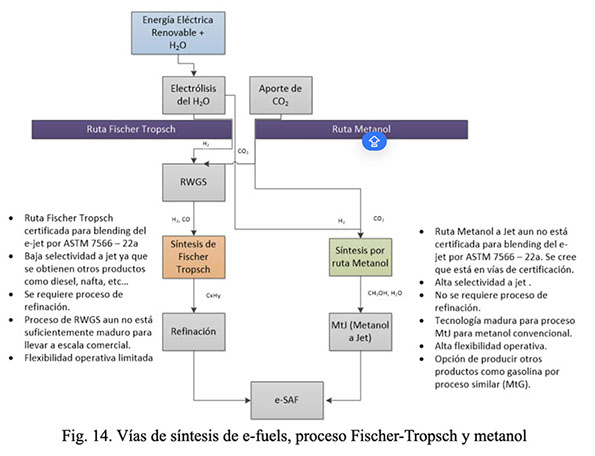
En la Fig. 14 se muestran las rutas resumidas de síntesis de e-fuels con los productos obtenidos, donde se observa la selectividad de la vía metanol. Esta es altamente selectiva a la generación de gasolina (para el proceso MTG) o jet (para el proceso MTJ).
La norma ASTM D7566 establece las tecnologías y materias primas autorizadas para producir combustible sintético de aviación. Entre las rutas de síntesis aprobadas se encuentra el proceso Fischer-Tropsch, que permite mezclar hasta un 50% de combustible sintético con combustibles fósiles convencionales como Jet A o Jet A-1.
El combustible de aviación siempre deberá cumplir con las especificaciones definidas en la norma ASTM D1655, en la cual se definen todos los requisitos y especificaciones fisicoquímicas que debe alcanzar el jet de aviación, cualquiera sea su origen.
4- Proyectos de producción de combustibles renovables en el mundo
Identificando los sectores objetivo como la aviación y el sector marítimo, se están desarrollando en el mundo y puntualmente en América Latina, numerosos proyectos y pilotos de producción de e-SAF y otros e-fuels. En este apartado se mostrarán algunos proyectos principales en la región y el mundo.

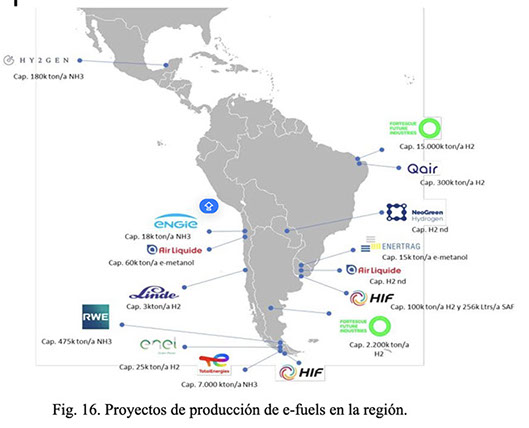
América Latina se está consolidando como una región estratégica para el desarrollo de combustibles sintéticos gracias a su abundancia de recursos renovables y su creciente compromiso con la descarbonización. A continuación, se detallan los principales proyectos en curso.
Chile se posiciona como el país más avanzado en la región en cuanto a producción de e-fuels, con varios proyectos entre los que se destacan:
Proyecto Haru Oni (Región de Magallanes): Desarrollado por HIF Global en colaboración con Siemens Energy y Porsche, planta demostrativa produce metanol y gasolina sintética a partir de energía eólica y CO₂ capturado. Su capacidad inicial es de 130.000 litros anuales, con planes de expansión industrial y el desarrollo de jet sintético.
Proyectos de Air Liquide y Linde: En 2021, la agencia estatal CORFO (Chile) adjudicó seis proyectos de hidrógeno verde a empresas como Air Liquide, Linde, Enel, INERATEC y Engie. Estas iniciativas, ubicadas en las regiones de Antofagasta, Valparaíso, Biobío y Magallanes, suman una capacidad de electrólisis de 388 MW y una inversión estimada de 1.000 millones de dólares. Se espera que entren en operación antes de 2030 y produzcan más de 45.000 toneladas de hidrógeno verde anualmente.
HIF Global, anunció su primer proyecto en Brasil, tras firmar hoy un contrato de reserva de suelo con el Puerto de Açu, uno de los principales puertos de Brasil, para desarrollar una instalación que producirá hasta 800.000 toneladas anuales de de e-Metanol. Por su parte, la empresa SEMPEN y el Puerto de Açu firmaron un acuerdo de reserva de área para la instalación de una planta de producción de amoníaco verde. El proyecto se ubicará en el polo de hidrógeno bajo en carbono del complejo portuario-industrial, en el norte del estado de Río de Janeiro. La planta tendrá una capacidad de producción de un millón de toneladas por año y la decisión final de inversión (FID) está programada para 2027-2028, con operación a partir de 2030.
En Argentina, en la región patagónica, se están explorando oportunidades para la producción de e-fuels aprovechando el alto potencial eólico. El proyecto Eco Refinerías del Sur (avalado por el gobierno de Chubut) proyecta una producción inicial de 100.000 toneladas de SAF al año, volumen suficiente para abastecer grandes aeropuertos empleando energía renovable de la Patagonia. Por su parte, el Proyecto Gaucho (Santa Cruz) de RP Global lanzó a finales de 2024 formalmente la puesta en marcha de su proyecto para instalar 3 GW de capacidad de electrólisis a partir de la generación eólica, en la provincia de Santa Cruz, como parte de la primera fase de su proyecto para generar amoniaco verde. La iniciativa utilizará un parque eólico de 4.2 GW para alimentar electrolizadores, generando más de 21.340 GWh de electricidad al año y produciendo hasta 1.7 millones de toneladas de amoníaco verde anuales, principalmente para exportar a Europa.
5- Análisis del potencial de Argentina para la producción y exportación de combustibles sintéticos renovables de origen no biológico:
Argentina se caracteriza por una amplia gama de recursos energéticos. Cuenta con una de las reservas de gas y petróleo no convencionales más grandes del mundo. El gas natural es la principal fuente de energía del país. Sin embargo, Argentina también posee un gran potencial para convertirse en un actor relevante en la producción y exportación de combustibles sintéticos renovables, gracias a su abundante disponibilidad de recursos de energía limpia.
El Atlas Global PtX (Power-to-X) encuentra que el 80 % del área global identificada con potencial para producir PtX se concentra en solo 10 países. Argentina tiene el tercer potencial más grande del mundo, después de Estados Unidos y Australia. Este potencial se ha identificado con respecto no solo a las energías renovables, sino también a la disponibilidad de agua, que es clave en la etapa de electrólisis para la producción de hidrógeno renovable.
El país cuenta con un escenario favorable para la producción de combustibles sintéticos por la alta capacidad para producir energía eléctrica renovable a un menor costo que otros mercados del mundo como el europeo, lo cual implica una ventaja competitiva a la hora de producir e-fuels para uso interno o para exportación.
En lo referente a la exportación de e-fuel y su transporte, en Argentina se cuenta con refinerías para los procesos de Downstream, contando con infraestructura para transporte de combustibles, o instalaciones para procesos de upgrading. También el país cuenta con puertos, zonas francas por donde estos combustibles pueden ser transportados en buques o barcazas y exportados a su destino final. O bien, los cruceros o grandes barcos pueden abastecerse de combustible ship-to-ship en el mismo puerto, lo cual disminuiría el costo de que el vehículo cargue e-fuel en otro puerto extranjero.
Es interesante el potencial que tiene Argentina, y la región para la producción y exportación de este tipo de combustibles, que serán claves a futuro en el marco de la transición energética.
La demanda europea será clave para la visualización de oportunidades de negocio en esta industria.
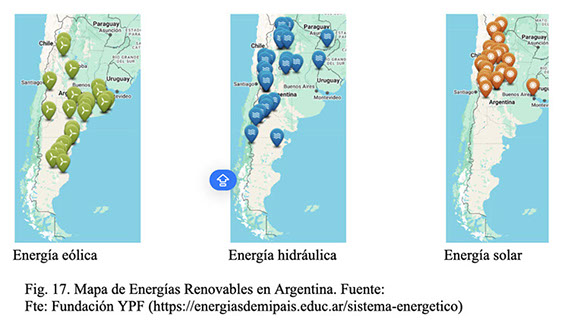
A continuación, en la Fig. 17, pueden verse los principales sitios de producción de energía eléctrica renovable en Argentina.
Las fuentes de CO2 biogénico disponibles teniendo en cuenta proyectos de producción de bioetanol o de biogás en Argentina se observan en la Fig. 18.
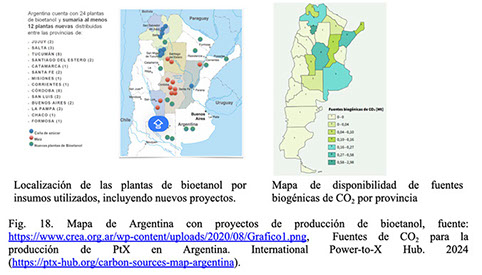
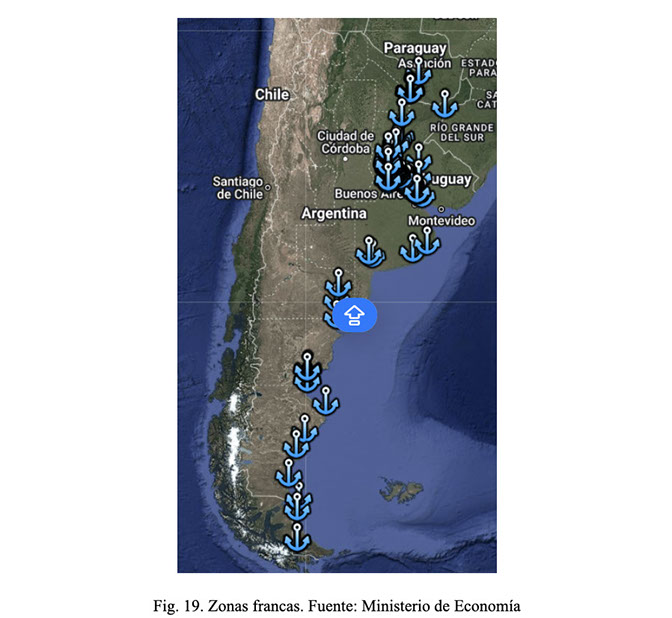
La Fig. 19 detalla la ubicación de puertos y zonas francas del país, lugares estratégicos para la importación de insumos, maquinaria y tecnología para la producción de este tipo de combustibles y la exportación del producto final terminado.
En el siguiente enlace que se adjunta, se muestran los oleoductos y gasoductos con los que cuenta Argentina. Es importante destacar la gran cantidad de gasoductos y oleoductos que posee el país, interconectados con las refinerías y los centros más grandes de procesamiento de crudo, una ventaja para transportar y procesar los crudos sintéticos.
Gasoductos y Oleoductos y logística de combustibles en Argentina. Fuente: Secretaría de Energía (http://datos.energia.gob.ar/dataset/mapas-de-transporte-de-hidrocarburos).
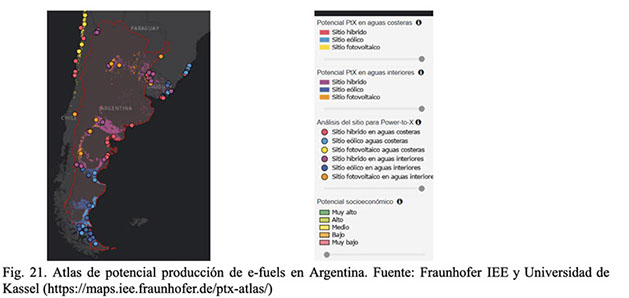
Para finalizar, en la Fig. 21 se muestra Argentina en el Global PtX Atlas del Fraunhofer IEE, un atlas interactivo que muestra el potencial global para la producción de combustibles. Este atlas analiza factores como:
✔ Potencial de generación de energía renovable (solar y eólica).
✔ Costos de producción de combustibles PtX.
✔ Viabilidad socioeconómica y geográfica.
✔ Posibilidades de exportación, especialmente hacia la Unión Europea
En el caso de Argentina, el mapa muestra:
Zonas con alto potencial solar y eólico, especialmente en regiones como la Patagonia, Cuyo y partes del NOA.
Áreas costeras e interiores que podrían ser aptas para instalaciones de producción de hidrógeno verde y otros combustibles sintéticos.
Evaluaciones de costos que indican que Argentina podría ser competitiva en la producción de PtX, gracias a sus recursos naturales y disponibilidad de espacio.
Capacidad de exportación hacia Europa, lo que posiciona al país como un actor potencial en el mercado internacional de energías limpias.
Conclusiones
Los e-fuels emergen como una solución estratégica ante las regulaciones internacionales cada vez más exigentes, como FuelEU Maritime para la U.E. y la IMO en el sector marítimo, y ReFuelEU Aviation en la U.E. o el plan CORSIA en el sector aéreo. Estos sectores (aviación y marítimo) son los que estarán más comprometidos a mediano y largo plazo con la descarbonización, y son difícilmente electrificables. En este contexto, solo la incorporación de combustible sustentable podrá viabilizar el alcance del objetivo Net Zero a 2050. Proyectos en desarrollo a nivel global consolidan su papel clave en la descarbonización del transporte aéreo y marítimo.
Argentina, y la región tienen un importante potencial para la producción de e-fuels. Argentina en particular cuenta con recursos naturales como agua, grandes extensiones de tierra, energía eléctrica renovable a precio muy competitivo y fuentes de CO2 biogénicas. También cuenta con zonas francas habilitadas para la exportación de combustibles, y también cuenta con una importante red logística de tuberías para transporte de hidrocarburos a lo largo de todo el país.
Por otra parte, la Unión Europea ya proyecta que, para el sector aviación, tendrá que importar parte del SAF a incorporar para cumplir con sus regulaciones a futuro.
Esto deja a la luz una importante oportunidad de negocio para Argentina y toda la región para poder ser proveedores de ese SAF que será requerido a mediano y largo plazo.
Hoy los biocombustibles son la respuesta ante el escenario de transición energética en los procesos y actividades, estos cuentan con una alta maduración de las tecnologías para su producción y un precio competitivo, sin embargo, los bio-combustibles tienen limitaciones, por ejemplo con la materia prima ya que la misma, en muchos casos compite con la producción de alimentos, y por lo tanto, las regulaciones serán a futuro cada vez más restrictivas en los tipos de materias primas para su producción. Por lo tanto, los e-fuels serán clave para la transición energética ya que serán complementarios a los bio-combustibles para el cumplimiento de las regulaciones y alcanzar en 2050 el objetivo de Net Zero emisiones.
Bibliografía
1. Sustainable synthetic carbon-based fuels for transport: Policy briefing Issued: September 2019 DES6164 ISBN: 978-1-78252-422-9 © The Royal Society
2. https://www.icao.int/Newsroom/Pages/First-sustainable-aviation-fuel-batches-certified-under-CORSIA.aspx
3. IRENA AND METHANOL INSTITUTE (2021), Innovation Outlook : Renewable Methanol, International Renewable Energy Agency, Abu Dhabi.
4. A look into the role of e-fuels in the transport system in Europe (2030–2050). https://www.concawe.eu/wp-content/uploads/E-fuels-article.pdf
5. e-Methanol. A universal green fuel. Siemmens Energy (https://www.siemens-energy.com/global/en/home/publications/whitepaper/download-e-methanol-white-paper.html)
6. https://www.exxonmobil.com/en/aviation/knowledge-library/resources/mtj-a-new-route-to-saf
7. https://www.topsoe.com/our-resources/knowledge/our-products/process-licensing/mtjet-process
8. https://uop.honeywell.com/en/industry-solutions/renewable-fuels/efining
9. Avances en Energías Renovables y Medio Ambiente Vol. 25, pp. 426-436, 2021 ISSN 2796-8111 TRANSICIÓN ENERGÉTICA Y DESARROLLO PRODUCTIVO LOCAL. COGENERACIÓN A PARTIR DE BIOMASA EN LA INDUSTRIA AZUCARERA EN TUCUMÁN S. Garrido
10. http://www.minagri.gob.ar/sitio/areas/bioenergia/biogas/
11. Ref https://www.magyp.gob.ar/sitio/areas/bioenergia/informes/bioetanol.php
12. IRENA (2020), Green Hydrogen Cost Reduction: Scaling up Electrolysers to Meet the 1.5⁰C Climate Goal, International Renewable Energy Agency, Abu Dhabi.
13. https://www.europarl.europa.eu/RegData/etudes/BRIE/2022/698900/EPRS_BRI(2022)698900_EN
14. Atlas de potencial global Power-to-X de Fraunhofer IEE y la Universidad de Kassel. https://maps.iee.fraunhofer.de/ptx-atlas/
15. Generación renovable variable. Energías Renovables, Integración y Despacho. Cammesa, actualizado septiembre 2023. https://cammesaweb.cammesa.com/
16. Mapa elaborado por Ignacion Romero. https://www.google.com/maps/d/viewer?mid=1UysUb8FChApZinkp6a30jq6G08-IBnPM&ll=-40.24984353816575%2C-58.88606313261141&z=4
17. https://www.santafe.gob.ar/ms/enerfe/2021/05/21/bioenergias/
18. https://www.seedsenergygroup.com/plantas
19. https://www.casarosada.gob.ar/informacion/actividad-oficial/9-noticias/41163-entro-en-operaciones-la-planta-de-biogas-san-pedro-verde-en-santa-fe
20. https://www.crea.org.ar/wp-content/uploads/2020/08/Grafico1.png
21. https://www.argentina.gob.ar/sites/default/files/listado_plantas_de_energia_renovable_0.pdf
22. Potencia Instalada. Generación renovable alcanzada por el Régimen de Fomento contemplado en la Ley N° 26.190 sus modificatorias y/o complementarias. Potencia Instalada por Región y Tecnología. https://cammesaweb.cammesa.com/potencia-instalada/?doing_wp_cron=1701087058.9500749111175537109375
23. Análisis del potencial de replicabilidad y transferibilidad del proyecto LIFE CO2IntBio. Plan de replicabilidad. PROYECTO CO2IntBIO LIFE 18 CCM/ES/001094 Junio 2022 http://www.lifeco2intbio.eu/sites/default/files/2023-06/Plan%20de%20Replicabilidad.pdf
24. Ref: H2B2 company
25.
https://www.cac-synfuel.com/en/kerosene
26. European e-fuels Conference 2023/2024.




> SUMARIO DE NOTAS
TRANSICIÓN ENERGÉTICA. PRODUCCIÓN DE E-FUELS PARA LOS SECTORES DE AVIACIÓN Y MARÍTIMO
MODELIZACIÓN DE EMISIONES DE GHG EN LA PLANIFICACIÓN DE LA REFINERÍA
UN ENFOQUE PASO A PASO PARA REDUCIR LA HUELLA DE CO₂ A TRAVÉS DE UNIDADES SRU
IMPLEMENTACIÓN DE TECNOLOGÍA DE GEMELO DIGITAL COMO SISTEMA DE MANEJO DE LA ENERGÍA EN REFINERÍA CAMPANA
> Ver todas las notas


Instituto Argentino del Petróleo y del Gas
Maipú 639 (C1006ACG) - Tel: (54 11) 5277 IAPG (4274)
Buenos Aires - Argentina
> SECCIONES
> NUESTRAS REDES
Copyright © 2025, Instituto Argentino del Petróleo y del Gas,todos los derechos reservados